How to set up Elasticsearch benchmarking, using Elastic’s own tools, is a necessity in today’s eCommerce. In my previous articles, I describe how to operate Elasticsearch in Kubernetes and how to monitor Elasticsearch. It’s time now to look at how Elastic’s homegrown benchmarking tool, Rally, will increase your performance, while saving you unnecessary cost, and headaches.
This article is part one of a series. This first part provides you with:
- a short overview of Rally
- a short sample track
Why to Benchmark in Elasticsearch with Rally?
Surely, you’re thinking, why should I benchmark Elasticsearch, isn’t there a guide illustrating the best cluster specs for Elasticsearch, eliminating all my problems?
The answer: a resounding “no”. There is no guide to tell you how the “perfect” cluster should look.
After all, the “perfect” cluster highly depends on your data structure, your amount of data, and your operations against Elasticsearch. As a result, you will need to perform benchmarks relevant to your unique data and processes to find bottlenecks and tune your Elasticsearch cluster.
What does Elastic’s Benchmarking Tool Rally Do?
Rally is the macro-benchmarking framework for Elasticsearch from elastic itself. Developed for Unix, Rally runs best on Linux and macOS but also supports Elasticsearch clusters running Windows. Rally can help you with the following tasks:
- Setup and teardown of an Elasticsearch cluster for benchmarking
- Management of benchmark data and specifications even across Elasticsearch versions
- Running benchmarks and recording results
- Finding performance problems by attaching so-called telemetry devices
- Comparing performance results and export them (e.g., to Elasticsearch itself)
Because we are talking about benchmarking a cluster, Rally also needs to fit the requirements to benchmark clusters. For this reason, Rally has special mechanisms based on the Actor-Model to coordinate multiple Rally instances, like a “cluster” to benchmark a cluster.
Basics about Rally Benchmarking
Configure Rally using the rally.ini file. Take a look here to get an overview of the configuration options.
Within Rally, benchmarks are defined in tracks. A track contains one or multiple challenges and all data needed for performing the benchmark.
Data is organized in indices and corporas. The indices include the index name and index settings against which the benchmark must perform. Additionally, the indices include the corpora, which contains the data to be indexed.
And, sticking with the “Rally” theme, if we run a benchmark, we call it a race.
Every challenge has one or multiple operations applied in a sequence or parallel to the Elasticsearch.
An operation, for example, could be a simple search or a create-index. It’s also possible to write simple or more complex operations called custom runners. However, there are pre-defined operations for the most common tasks. My illustration below will give you a simple overview of the architecture of a track:
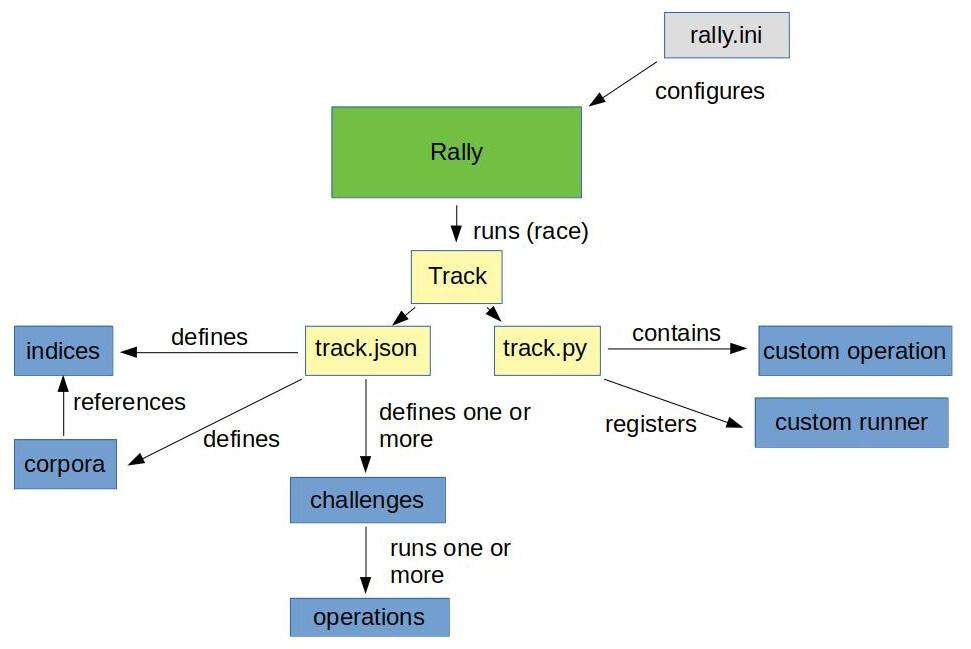
Note: the above image supplies a sample of the elements within a track to explain how the internal process looks.
Simple sample track
Below, an example of a track.json and an index-with-one-document.json for the index used in the corpora:
{
"version": 2,
"description": "Really simple track",
"indices": [
{
"name": "index-with-one-document"
}
],
"corpora": [
{
"name": "index-with-one-document",
"documents": [
{
"target-index": "index-with-one-document",
"source-file": "index-with-one-document.json",
"document-count": 1
}
]
}
],
"challenges": [
{
"name": "index-than-search",
"description": "first index one document, then search for it.",
"schedule": [
{
"operation": {
"name": "clean elasticsearch",
"operation-type": "delete-index"
}
},
{
"name": "create index index-with-one-document",
"operation": {
"operation-type": "create-index",
"index": "index-with-one-document"
}
},
{
"name": "bulk index documents into index-with-one-document",
"operation": {
"operation-type": "bulk",
"corpora": "index-with-one-document",
"indices": [
"index-with-one-document"
],
"bulk-size": 1,
"clients": 1
}
},
{
"operation": {
"name": "perform simple search",
"operation-type": "search",
"index": "index-with-one-document"
}
}
]
}
]
}
index-with-one-document.json:
{ "name": "Simple test document." }
The track above contains one challenge, one index, and one corpora. The corpora refers to the index-with-one-document.json, which includes one document for the index. The challenge has four operations:
delete-index → delete the index from Elasticsearch so that we have a clean environment create-index → create the index we may have deleted before Bulk → bulk index our sample document from index-with-one-document.json. Search → perform a single search against our index
Taking Rally for a Spin
Let’s race this simple track and see what we get:
(⎈ |qa:/tmp/blog)➜ test_track$ esrally --distribution-version=7.9.2 --track-path=/tmp/blog/test_track
____ ____
/ __ \____ _/ / /_ __
/ /_/ / __ `/ / / / / /
/ _, _/ /_/ / / / /_/ /
/_/ |_|\__,_/_/_/\__, /
/____/
[INFO] Preparing for race ...
[INFO] Preparing file offset table for [/tmp/blog/test_track/index-with-one-document.json] ... [OK]
[INFO] Racing on track [test_track], challenge [index and search] and car ['defaults'] with version [7.9.2].
Running clean elasticsearch [100% done]
Running create index index-with-one-document [100% done]
Running bulk index documents into index-with-one-document [100% done]
Running perform simple search [100% done]
------------------------------------------------------
_______ __ _____
/ ____(_)___ ____ _/ / / ___/_________ ________
/ /_ / / __ \/ __ `/ / \__ \/ ___/ __ \/ ___/ _ \
/ __/ / / / / / /_/ / / ___/ / /__/ /_/ / / / __/
/_/ /_/_/ /_/\__,_/_/ /____/\___/\____/_/ \___/
------------------------------------------------------
| Metric | Task | Value | Unit |
|---------------------------------------------------------------:|--------------------------------------------------:|------------:|-------:|
| Cumulative indexing time of primary shards | | 8.33333e-05 | min |
| Min cumulative indexing time across primary shards | | 8.33333e-05 | min |
| Median cumulative indexing time across primary shards | | 8.33333e-05 | min |
| Max cumulative indexing time across primary shards | | 8.33333e-05 | min |
| Cumulative indexing throttle time of primary shards | | 0 | min |
| Min cumulative indexing throttle time across primary shards | | 0 | min |
| Median cumulative indexing throttle time across primary shards | | 0 | min |
| Max cumulative indexing throttle time across primary shards | | 0 | min |
| Cumulative merge time of primary shards | | 0 | min |
| Cumulative merge count of primary shards | | 0 | |
| Min cumulative merge time across primary shards | | 0 | min |
| Median cumulative merge time across primary shards | | 0 | min |
| Max cumulative merge time across primary shards | | 0 | min |
| Cumulative merge throttle time of primary shards | | 0 | min |
| Min cumulative merge throttle time across primary shards | | 0 | min |
| Median cumulative merge throttle time across primary shards | | 0 | min |
| Max cumulative merge throttle time across primary shards | | 0 | min |
| Cumulative refresh time of primary shards | | 0.000533333 | min |
| Cumulative refresh count of primary shards | | 3 | |
| Min cumulative refresh time across primary shards | | 0.000533333 | min |
| Median cumulative refresh time across primary shards | | 0.000533333 | min |
| Max cumulative refresh time across primary shards | | 0.000533333 | min |
| Cumulative flush time of primary shards | | 0 | min |
| Cumulative flush count of primary shards | | 0 | |
| Min cumulative flush time across primary shards | | 0 | min |
| Median cumulative flush time across primary shards | | 0 | min |
| Max cumulative flush time across primary shards | | 0 | min |
| Total Young Gen GC | | 0.022 | s |
| Total Old Gen GC | | 0.033 | s |
| Store size | | 3.46638e-06 | GB |
| Translog size | | 1.49012e-07 | GB |
| Heap used for segments | | 0.00134659 | MB |
| Heap used for doc values | | 7.24792e-05 | MB |
| Heap used for terms | | 0.000747681 | MB |
| Heap used for norms | | 6.10352e-05 | MB |
| Heap used for points | | 0 | MB |
| Heap used for stored fields | | 0.000465393 | MB |
| Segment count | | 1 | |
| Min Throughput | bulk index documents into index-with-one-document | 7.8 | docs/s |
| Median Throughput | bulk index documents into index-with-one-document | 7.8 | docs/s |
| Max Throughput | bulk index documents into index-with-one-document | 7.8 | docs/s |
| 100th percentile latency | bulk index documents into index-with-one-document | 123.023 | ms |
| 100th percentile service time | bulk index documents into index-with-one-document | 123.023 | ms |
| error rate | bulk index documents into index-with-one-document | 0 | % |
| Min Throughput | perform simple search | 16.09 | ops/s |
| Median Throughput | perform simple search | 16.09 | ops/s |
| Max Throughput | perform simple search | 16.09 | ops/s |
| 100th percentile latency | perform simple search | 62.0082 | ms |
| 100th percentile service time | perform simple search | 62.0082 | ms |
| error rate | perform simple search | 0 | % |
--------------------------------
[INFO] SUCCESS (took 39 seconds)
--------------------------------
Parameters we used:
- distribution-version=7.9.2 → The version of Elasticsearch Rally should start/use for benchmarking.
- track-path=/tmp/blog/test_track → The path to our track location.
As you can see, Rally provides us a summary of the benchmark and information about each operation and how they performed.
Rally Benchmarking in the Wild
This part-one introduction to Rally Benchmarking hopefully piqued your interest for what’s to come. My next post will dive deeper into a more complex sample. I’ll use a real-world benchmarking scenario within OCSS (Open Commerce Search Stack) to illustrate how to export benchmark-metrics to Elasticsearch, which can then be used in Kibana for analysis.