We’re committed to fostering a culture at searchHub that prioritizes continuous learning and rapid innovation. It’s super important to us that the development and use of new products and features by our teams enhances the search and recommendation algorithms of our customers. These things have to have a quantifiable positive impact on their business objectives and success metrics. For this reason, no small part of our decision-making process involves meticulous data analysis through well-designed experiments, commonly referred to as A/B tests.

A/B Testing for Search is Different
Conducting A/B testing for search involves various considerations, as there is no one-size-fits-all approach. (we have already covered this topic on several occasions, both here and here).
Choosing a specific metric to evaluate is important, such as click-through rate (CTR), mean reciprocal rank (MRR), conversion rate (CR), revenue, or other relevant search success indicators. From there, determining the optimal duration for each test is critical. This is necessary to achieve any statistical significance & weight, considering the potential impact of a novelty effect. Contrary to what we’d all like to believe, A/B testing for search is not a simple switch or additional add-on. It’s a scientific process that requires thoughtful planning and analysis.
From Sessions to Search-Trails as randomization unit
When scoping a search A/B test, it is advisable to consider search-trails. Here are some reasons why:
- Too strong a focus on user sessions can sometimes disconnect cause and effect in eCommerce. User sessions often involve various actions that may be unrelated, potentially resulting in the identification of differences irrelevant to the search experience. Additionally, search queries are far from normally distributed over your user base – consequently, user-splitting dramatically reduces the number of tests you can do in parallel.
- Conversely, relying on individual search queries may lead to scenarios where improvements made to targeted queries adversely impact other queries’ performance within the same search sessions.
This is why, once we began getting into the weeds, our initial step was to shift the randomization unit from users to query-search-trails. A query-search-trail is like a micro-session beginning with an intent (query) and ending with actions/events that change the intent (more details can be found here). This adjustment allows us to make the most of the available traffic for each query, utilizing every search query from every user. With user sessions typically encompassing various search paths, we can now harness this wealth of information to enhance the robustness of our experiments.
Along the way, we were surprised to discover, compared to traditional user-based randomization, how the number of query experiments with valid results are significantly boosted by our decision to focus on query-search-tails. We’re talking almost about an increase in order of magnitude. However, it does introduce certain challenges. Most notably, we need to come up with a different way to handle late interaction events, like checkouts. These have the potential to compromise the independence assumption.

Automatically detecting and creating Query Experiments
Considering that the majority of our customers deal with hundreds of thousands or even millions of diverse search queries, and still aspire to enhance their north-star search Key Performance Indicators (KPIs) at scale, it is evident that solely relying on users to manually create experiments is impractical.
So, we designed a pipeline capable of automatically identifying query pairs. These query pairs have to, on the one hand, provide enough value to warrant comparison in the first place (that means show enough difference), while also providing evidence that they will produce valid results based on predefined experimentation parameters. The current pipeline is capable of generating and running thousands of query experiments simultaneously across our user base. On top of that, it has proven to be a valuable resource for conducting efficient experiments that contribute to search optimization.
Tackling imbalanced and sparse Search Experimentation data
Above, I mentioned our decision to employ Search-Trails as a randomization unit. Despite the discussed advantages and disadvantages, the reality is that a significant portion of search-related events are both sparse and imbalanced. To illustrate what I mean: There are instances where merely 10% of the queries receive 90% of the traffic. For the longtail, this means relatively few interactions, such as clicks or adding items to carts. Although our intent-clustering approach effectively mitigates data sparsity in interaction data to a considerable extent, our primary focus remains centered on addressing the imbalance of the experimental data.
An example of an experiment with imbalanced data:
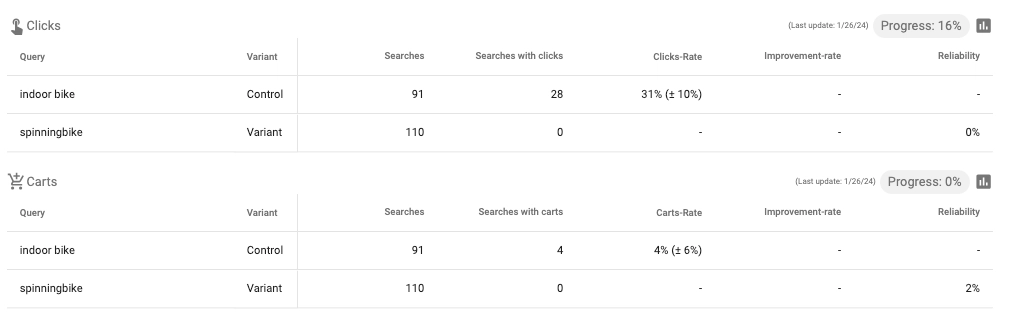
Managing imbalanced data in experiments is challenging – (also referred to as SRM). It also has the side effect of significantly impacting the statistical power of your experiments. To maintain the desired power level, a larger minimum sample size is necessary. Naturally, acquiring larger sample sizes becomes problematic when dealing with imbalanced data.
We adopted two strategies to address this challenge:
- Maximize efficiency by minimizing the required minimum sample size or run-time. To achieve this, we employ techniques such as CUPED and GST while maintaining power levels. Particularly in the context of an automated experiment creation system, accurately identifying efficiency and futility boundaries is crucial for driving incremental improvements through experimentation.
Surprisingly, we discovered ways to substantially diminish this imbalance. How?
- Well, it turns out that within a session, we can influence the likelihood of a user triggering a specific query through auxiliary systems designed to assist users in formulating their queries (such as suggestions, query recommendations, etc.). This approach significantly reduces the imbalance in the majority of cases we encountered.

TESUTO - Granular Search Experimentation @scale
Over the past few months, we’ve gradually introduced our “Query Testing” capability, powered by TESUTO, to our customer base. The advantages of granular experimentation at scale are increasingly apparent. Simple modifications in search functionality, such as incorporating synonyms, adjusting field-boosts, or modifying the product assortment, are now evaluated based on real data rather than relying solely on intuition.
If you’re interested in leveraging the benefits of Query Testing, please don’t hesitate to click on the button and reach out to us.
For those curious about how we developed TESUTO, including GST, CUPED, and more, stay tuned for upcoming blog posts where we delve into these topics in more detail.




