Find Your Application
Development Bottleneck
A few months ago, I wrote about how hard it is to auto-scale people. Come to think of it, it’s not hard. It’s impossible. But, fortunately, it works pretty well for our infrastructure.
When I started my professional life more than 20 years ago, it became more and more convenient to rent a hosted server infrastructure. Usually, you had to pick from a list of potential hardware configurations your favorite provider was supplying. At that time, moving all your stuff from an already running server to a new one wasn’t that easy. As a result, the general rule-of-thumb was to configure more MHz, MB, or Mbit than was needed during peak times to prepare for high season. In the end, lots of CPUs were idling around most of the year. It’s a bit like feeding your 8-month-old using a bucket. Your kid certainly won’t starve, but the mess will be enormous.
Nowadays, we take more care to efficiently size and scale our systems. With that, I mean we do our best to find the right-sized bottle with a neck broad enough to meet our needs. The concept is familiar. We all know the experiments from grade school comparing pipes with various diameters. Let’s call them “bottlenecks.” The smallest diameter always limits the throughput.
A typical set of bottlenecks looks like this:
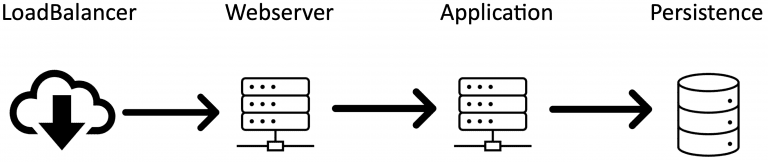
Of course, this is oversimplified. There’s also likely to be a browser, maybe an API-Gateway, some firewall, and various NAT-ting components as well in a real-world setting. All these bottlenecks directly impact your infrastructure. Therefore, it’s crucial for your application that you find and broaden your bottlenecks in a way that enough traffic can fluently run through them. So let me tell you three of my favorite bottlenecks of the last decade:
My Three Favorite Application Development Bottlenecks
1. Persistence:
Most server systems run on a Linux derivative. When an application creates data (regular files, logfiles, search indexes) to some kind of persistence in a Linux system, it is not written immediately. Instead, the Linux kernel will tell your application: “alright, I’m done,” although it isn’t. Instead, the data is temporarily kept in memory – which may be 1000 times faster than actually writing it to a physical disk. That’s why it’s no problem at all if another component wants to access that same data only microseconds later. The Linux kernel will serve it from memory as if read from the disk. That’s one of the main breakthroughs Linus Torvalds achieved with his “virtual machine architecture” in the Linux kernel (btw: Linus’ MSc thesis is a must-read for everyone trying to understand what a server is actually doing. In the background, the kernel will, of course, physically write the data to the disk. You’ll never notice this background process as long as there is a good balance between data input and storage performance. Yet, at some point, the kernel is forced to tell your application: “wait a second, my memory is full. I need to get rid of some of that stuff.” But when exactly does this happen?
Execute the following on your machine: sysctl -a | grep -P “dirty_.*_ratio”
Most likely you’ll see something like vm.dirty_background_ratio = 10
vm.dirty_ratio = 20_
These are the defaults in most distributions. vm.dirty_ratio is the percentage of RAM that may be filled with unwritten data before it is forced to be written to disk. These values were introduced many years ago when servers had far less than 1 GB of RAM. Imagine a 64GB server system and an application that is capable of generating vast amounts of data in a short time. Not that unusual for a search engine running a full update on an index or some application exporting data. As soon as there are 12.8GB of unwritten data, the kernel will more or less stop your system and write 6.4GB physically to the disk until the vm.dirty_background_ratio limit is reached again. Have you ever noticed a simple “ls” command in your shell randomly taking several seconds or even longer to run? If so, you’re most likely experiencing this “stop-the-world! I-need-to-sync-this-data-first.” How to avoid such behavior and adequately tune your system to keep it from coming back again may be crucial in fixing this random bottleneck. Read more in Bob Planker’s excellent post – it dates a few years back yet still fresh as ever: I often find myself coming back to it. You may want to set a reasonably low value for dirty_ratio to avoid long suspension times in many cases.
BTW: want to tune your dev machine? Bear in mind that your IDE’s most significant task is to write temporary files (.class files to run a unit-test, write .jar files that will be recreated later anyway, node packages, and so on), so you can increase the vm.dirty_ratio to 50 or more. On a system with enough memory, this will render your slow IDE into a blazingly fast in-memory-IDE.
2. Webserver:
I love web servers. They are the Swiss Army Knife of the internet. Any task you can think of they can do. I’ve even seen them perform tasks that you don’t think about. For example, they can tell you that they are not the coffee machine, and you mistakenly sent your request to the teapot. Webservers accomplish one thing extraordinarily well: they act as an interface for an application server. Quite a typical setup is an Apache Webserver in front of an Apache Tomcat. Arguably, this is not the most modern of software stacks, but you’ll be surprised how many companies still run it.
In an ideal world, the developer team manages the entire request lifecycle. After all, they are the ones who know their webserver and develop the application that runs inside the tomcat appserver. As a result, they have sufficient access to the persistence layer. Our practical experience, however, leaves us confronted with horizontally cut responsibilities. In such cases, Team 1 is webserver; Team 2 takes care of the Tomcat; Team 3 develops the application, and Team 4 is the database engineers. I forgot about the load balancer, you say? Right, nobody knows precisely how this works, we’ve outsourced it.
One of my most favorite bottlenecks, in this scenario, looks something like the following. All parties did a great job developing a lightning-fast application that only sporadically has to execute long-running requests. Further, the database has been fine-tuned and set up with the appropriate indexes. All looks good, so you start load-testing the whole setup. The CPU-load on your application slowly ramps up; everything is relaxed. Then, suddenly, the load-balancer starts throwing health-check errors and begins marking one service after the other as unresponsive. After much investigation, tuning the health-check timeout, and repeatedly checking the application, you find out that the Apache cannot possibly serve more than 400 parallel requests. Why not? Because nobody thought to configure its limits so it’s still running on the default value:
Find your bottlenecks! Hard to find and easy to fix
3. Application:
Let’s talk about Java. Now, I’m sure you’ve already learned a lot about garbage collection (GC) in Java. If not – do so before trying to run a high-performance-low-latency application. There are tons of documents describing the differences between the built-in GCs – I won’t recite them all here. But there is one tiny detail I haven’t seen or heard of almost anywhere:
The matrix-like beauty of GC verbose logging

Have you ever asked yourself whether we live in a simulation? Although GC verbose logging cannot answer this for your personal life, at least it can answer it for your Java application. Imagine a Java application running on a VM or inside a cloud container. Usually, you have no idea what’s happening outside. It’s like Neo before swallowing the pill (was it the red one? I always mix it up). Only now, there is this beautiful GC log line:
2021-02-05T20:05:35.401+0200: 46226.775: [Full GC (Ergonomics) [PSYoungGen: 2733408K->0K(2752512K)] [ParOldGen: 8388604K->5772887K(8388608K)] 11122012K->5772887K(11141120K), [Metaspace: 144739K->144739K(1179648K)], 3.3956166 secs] [Times: user=3.39 sys=0.04, real=23.51 secs]
Did you see it? There is an error in the matrix. I am not talking about a full GC running longer than 3 seconds (which is unacceptable in a low-latency environment. If you’re experiencing this behavior, consider using another GC). I am talking about the real-world aging 23.51 seconds while your GC doesn’t do anything. How is that even possible? Time elapses identically for host and VM as long as they travel through the universe at the same speed. However, if your (J)VM says: “Hey, I only spent 3.39 seconds in GC while the kernel took 0.04 seconds. But wait a minute, in the end, 23.51 seconds passed. Whaa? Did I miss the party?” In this case, you’ll know quite for sure that your host system suspended your JVM for over 20 seconds. Why? Well I can’t begin to answer the question for your specific situation, but I have experienced the following reasons:
- Daily backup of ESX cluster set to always start at 20:00 hrs.
- Transparent Hugepages stalling the whole host to defrag memory (described first here)
- Kernel writing buffered data to disk (see: Persistence)
Additionally, there are other expedient use cases for using the GC logs for analysis (post-mortem analysis, tracking down suspension times in the GC, etc.). Before you start spending money on application performance monitoring tools, activate GC logging – it’s for free: -verbose:gc -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:/my/log/path/gclog.txt
Rest assured, finding and eliminating your bottlenecks is an ongoing process. Once you’ve increased the diameter of one bottle, you have to check the next one. Some call it a curse; I call it progress. And, it’s the most efficient use of our limited resources. Much better than feeding your kid from a bucket.