Query Understanding: How to really understand what customers want
- Part 1
When users search for things like “men’s waterproof jacket mountain equipment” they’re seeking help. What they expect is for the search engine to understand their intent, interpret it and return products, content or both that match. It’s essential for the search engine to differentiate types of products or content they are looking for. In this case, the customer is likely shopping for a jacket. Equipped with this domain-specific knowledge, we can tailor the search results page by displaying jacket-specific filters, banners and refine the search results by prioritizing or only showing jackets. This process is often called query-understanding. Many companies both site search vendors as well as retailers have tried developing, building and improving these systems but only few have made it work properly at large scale with manageable effort.
Query Interpretation the backstory
At the time of this post, all our customers combined sell
- more than 47 million different products
- in over 13 different languages
- across about 5.3 million unique search intent clusters.
- These clusters represent approximately 240 million unique search queries that cover
- a couple billion searches.
All our customers use some kind of taxonomy to categorize their products into thousands of “product classes”. Then they append attributes mainly for navigational purposes.
Examples of product classes include
- jackets
- waterproof jackets
- winter jackets
Query Classifier
The Query Classifier predicts product classes and attributes that customers are most likely to engage with, based on their search queries.
Once a query classifier accurately predicts classes and attributes, we can enrich the search-system with structured domain knowledge.
This transforms the search problem from purely searching for strings to searching for things.
The result is not only a dramatic shift in how product filters are displayed relative to their product classes, but also how these filters can be leveraged to boost search results using those same classes.
The Challenge
Deciphering, however, which types of products, content or attributes are relevant to a search query is a difficult task. Some considerations:
|
Challenge
|
Context
|
|---|---|
|
SCALE |
Every day, we help our customers optimize millions of unique search queries to search within millions of products. Both dimensions, the query-dimension and the product-dimension change daily. This makes scale a challenge already. |
|
LANGUAGE GAP |
Unfortunately, most of our customers are not focused on creating attributes and categories as a main optimization goal for their search & discovery systems. This leads to huge gaps when comparing the product catalog to the user query language. Additionally, every customer uses individual taxonomies making it hard to align different classes across all customers. |
|
SPARSITY |
A small percentage of queries explicitly mention product type making them easy to classify. Most queries do not. This forces us to take cues from users’ activities to help identify the intended product class. |
|
AMBIGUITY |
Some queries are ambiguous. For example, the query “desk bed” could refer to bunk beds with a desk underneath, or it could mean tray desks used in bed. |
While there isn’t much we can do about the first challenge, the good news is we already cluster search queries by intent. Knowing customer intent means searchhub can leverage all the information contained in these clusters to address challenges 3 and 4. Sparsity for example, is greatly reduced because we aggregate all query variants into clusters and use the outcome to detect different entities or types. Also the ambiguity challenge is greatly reduced as query clusters do not contain ambiguous variants. The clusters themselves, on the other hand, give us enough information to disambiguate.
Having solved problems 3, and 4, we are able to focus on addressing the Language gap problem and building a large scale, cost efficient Search Interpretation Service.
Our Approach
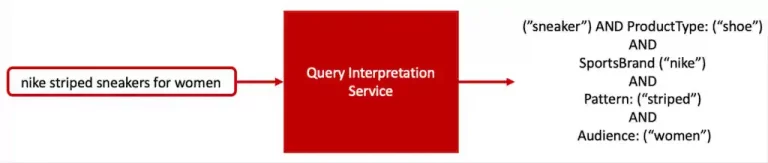
To tackle the query understanding challenge searchhub developed our so-called Search Interpretation Service to perform live search query understanding tasks. The main task of the Interpretation service is to predict the query’s relevant classes (attributes) for a given query in real-time. The output can then be consumed by several downstream Search applications. The Query Classifier model (NER-Service) powers one of these Interpretation microservices.
Once a query is submitted to the search interpretation service we start our NER-Service (named entity recognition and classification). This service identifies entities in user queries like brands, colors, product category, product type and product type specific attributes. All matched entities in the query are annotated with predefined tags. These tags & entities are based on our unified ontology which we’ll cover in a bit.
For the actual query annotation, we use an in-house Trie-based solution comparable to the common FST based SolrTextTagger, only an order of magnitude faster. Additionally, we can easily add and remove entities on the fly without re-indexation. Our solution extracts all possible entities from the query, disambiguates them and annotates them with the predefined tags.
Results
|
Challenge
|
Precision
|
Recall
|
F1
|
|---|---|---|---|
|
Baseline (productType) |
0.97 |
0.69 |
0.81 |
Since the detected entities in our case are applied to complete intent-clusters (representing sometimes thousands of search queries) rather than a single query, precision is of highest priority. We tried different approaches for this task but none of them gave us a precision close to what you see in the above table. Nevertheless, a quick glance and you’ll easily spot that “Recall” is the weakest part. The system is simply not equipped with enough relevant entities and corresponding tags. To learn these efficiently, the logical next step was to build a system able to automatically extract entities and tags based on available data sources. We decided to build a unified ontology and an underlying system that learns to grow this ontology on its own.
searchhub’s unified Ontology
Since taxonomies differ greatly across our customer base we needed an automated way to unify them, that would allow us to generate predictions across customers and languages. It’s essential we are able to use this ontology to firstly classify SKUs and secondly, use the classes (and subclasses) as named entities for our NER-service.
Since all existing ontologies we found tend to focus more on relationships between manufacturers and sellers, we needed to design our taxonomy according to a fundamentally different approach.
Our ontology requires all classes (and subclasses) to be as atomic as possible to improve recall.
“An atomic entity is an irreducible unit that describes a concept.” - Andreas Wagner
It also appends an “is-a” requirement on all subclasses for a given class. Additionally, we try to avoid combo classes unless they are sold as a set (dining sets that must contain both table and chairs). This requirement keeps the ontology simple and flexible.
What was our process for arriving at this type of ontological structure? We began by defining Product Types. From there we built the hierarchical taxonomy in a way that maximizes the query category affinity. In essence we try to minimize the entropy of the distribution of a search result set across its categories for our top-k most important queries.
Product Types
A Product Type is defined as the atomic phrase that describes what the customer is looking for.
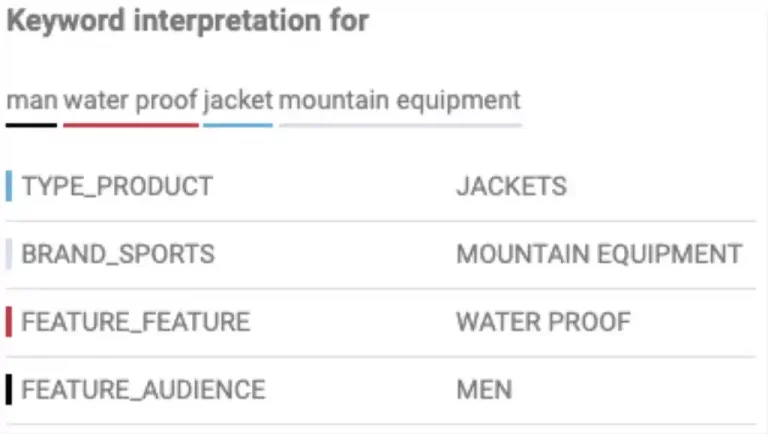
- Consider an example, “men’s waterproof jacket mountain equipment”.
- Here, the customer is looking for a jacket.
- It is preferable if the jacket is waterproof
- designed for men
- by the Brand Mountain Equipment
but these requirements are secondary to the primary requirement of it being a jacket. This means that any specialized product type must be stripped down to its most basic form jacket.
Attributes
An Attribute is defined as an atomic phrase that provides more information about a product type.
- Consider an example “bridgedale men’s merino hiker sock”.
- Here, we classify the term sock as a Product type
- and we can classify the remaining terms (bridgedale, men’s, merino and hiker) as Attributes and/or Features.
This gives us a lot of flexibility during recall. Attributes can be subclassed in Color, Material, Size, etc. depending on the category. But since our aim is to create a simplified ontology for search, we restrict attribute subclasses to what is actually important for search. This makes the system more maintainable.
Learning to grow ONTOLOGIES
Data Collection
It should be obvious that building and growing this type of ontology needs some sort of automation, otherwise our business couldn’t justify maintaining it. Our biggest information source is anonymous customer behavior data. So, after some data-analyses we were able to prove that customers generally add relevant products to their shopping cart during search. This allowed us to use historical user queries and the classes of the related products added-to-cart, within a search session, as the model development dataset. For this dataset we defined a search experience as the sequence of customer activities after submitting a search query and before moving on to a different activity. For each search experience, we collected the search query and the classes of the added-to-cart-products. Each data point in our dataset corresponds to one unique search experience from one unique customer.
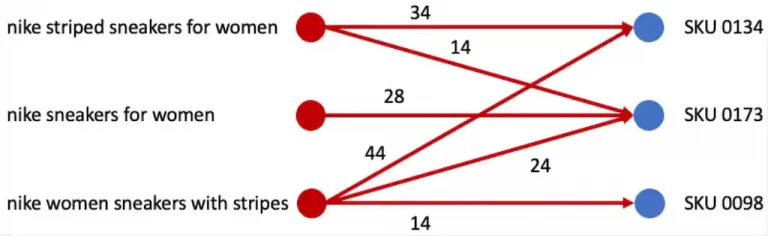
Connecting Queries and Signals
From here we build a bipartite graph that maps a customer’s search query to a set of added-to-cart-products – SKUs. This graph can be further augmented by all sorts of different interactions with products (Views, Clicks, Buys). We represent search queries and SKUs by nodes on the graph. An edge between a query and a SKU indicates that a customer searched for the query and interacted with the corresponding SKUs. The weight of the edge indicates the strength of the relationship between the query and the SKU. For the first model we simply modeled this strength by aggregating the number of interactions between the query and the SKU over a certain period of time. There are no edges between queries or between SKUs.
As broad queries like “cheap” or “clothing” might add a lot of noise to the data we use the entropy of a query across different categories to determine if it is broad and remove it from the graph. We use several heuristics to further augment and prune the graph. For example, we remove query-SKU pairs that have edge weights less than some predefined threshold. From here we have simply to find a way to compute a sorted list of Product sub-classes that are atomic and relevant for that category.
Extracting Product Entities
To our knowledge there exist several methods to automatically extract atomic Product entities from search queries and interaction data, but only one of them offered us what we needed. We required the method to be fully unsupervised, cost efficient and fast to update.
The Token Graph Method
This method is a simple unsupervised method for extracting relevant product metadata objects from a customer’s search query, and can be applied to any category without any previous data.
The fundamental principle behind it is as follows: If a query or a set of queries share the same interactions we can assume that all of them are related to each other, because they share some of the same clicked SKUs. In other words, they share the same intent. This principle is also known as universal-similarity and its fundamental idea is used in almost any modern ML-application.
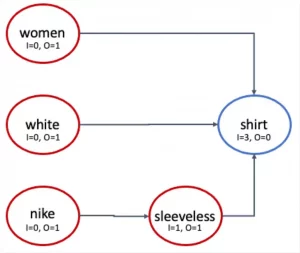
Now that we have a set of different queries that are related to each other we apply a trick.
Let us assume that we can detect common tokens (a token might be a single or multi-word-token) between the queries.
We can now create a new graph where each token is a node and there are edges between adjacent tokens.
The above figure shows the token graph for the query set {women shirt, white shirt, nike sleeveless white shirt}.
It is quite safe to say that in most cases, the product token is the last term in a query (searchub is almost able to guarantee this since we use aliases that represent our clusters that are created by our own language models). With this assumption the product token should be the node that maximizes the ratio (I /(O+I)) , where O = is the number of outgoing edges and I is the number of incoming edges for the node corresponding to the token. If the search query contains just a single token, we set I = O = 1.
We can further improve precision by requiring that I ≥ T , where T is some heuristic threshold. From here we can generate a potential product from each connected component and, aggregated over all connected components gives us a potential list of products. With this simple model we can not only extract new product types, we can actually leverage it further to learn to categorize these product types. Can you guess how ? 🙂
What's Next
This approach of using a kind of rule-based-system to extract, and an unsupervised method to learn these rules, seems too simple to produce good enough results, but it does and has one very significant advantage over most other methods. It is completely unsupervised. This allows it to be used without any training data from other categories.
Results
|
Challenge
|
Precision
|
Recall
|
F1
|
|---|---|---|---|
|
Baseline (productType) |
0.97 |
0.78 |
0.86 |
Additionally, this approach is incremental. This means we remain flexible, able to rollback almost instantly, all or only some newly learned classes in our ontology if something goes wrong. Currently we use this method as the initial step acting as the baseline for more advanced approaches. In the second part we’ll try some more sophisticated ways to further improve recall with limited data.