In 2017 we officially launched searchhub.io. Now 5 years later, it’s time for a recap and some updates regarding our goals, strategy, and product.
Has the Search Game Changed?
Maybe in scale, but certainly not in terms of goals and purpose. Search Engines still act as filters for the wealth of information available on the Internet. They allow users to quickly and easily find information that is of genuine interest or value to them, without the need to wade through numerous irrelevant web pages. However, they are built based on concepts that store words or vectors and not their meaning. Screen real estate is going to zero, and the way people can interact with digital systems has evolved from keyboard only to keyboard, voice, images, and gestures. All of these input types are error-prone and don’t include context. A well done site search, however, should cater to these errors and automatically add available context to come up with relevant answers.
Therefore, our motivation hasn’t changed. In fact, we are now even more convinced that there is an almost endless need and opportunity for Fast & Relevant search.
Our motivation “FAST & RELEVANT SEARCH” helps to craft meaningful search experiences for the people around us, this mission inspires us to jump out of bed each day and guides every aspect of what we do.
Was Our Entirely New Approach with searchHub.io a Success?
1. It Works Site Search Platform Independent…
…definitely yes. We still see a growing set of different search engines out there, and all of them have their pros and cons. Often the reason a specific search engine was chosen has nothing to do with the ability to successfully fulfill the basic use case of search. In more complex scenarios, there could even be a set of different search engines in production, each fulfilling a different use case. That’s why we designed searchHub as a platform independent proxy that automatically enhances existing site search engines by autocorrecting, aligning human input and building context around every search query in a way your search engine understands.
2. Enhance, Not Replace
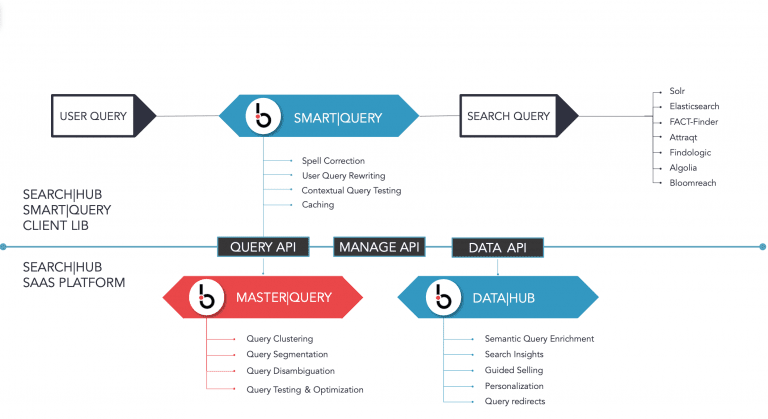
…absolutely yes. Search Engines are becoming an even more integral part of modern system backbones and are in most cases very hard to replace. But “search” as we know it is already changing because modern technology has set today’s customers very high expectations; they know what they want, and they want it now. More and more retailers have started investing in their own, business-case adapted, Search & Discovery Platforms. And they continue to add new in-house features like LTR (Learning-to-Rank), personalization, and searchandising more frequently than ever before.
Therefore, we decided early on that we are not aiming to replace these platforms and instead focus on how we can enable our customers to achieve even better results with what they have now or in the future at scale. That’s precisely why the technology behind searchHub was specifically designed to enhance our customers’ existing site search, not replace it. The primary component is still our Lambda-Architecture that enables us and our customers to separate model training from model serving.
3. The Lambda-Architecture Choice
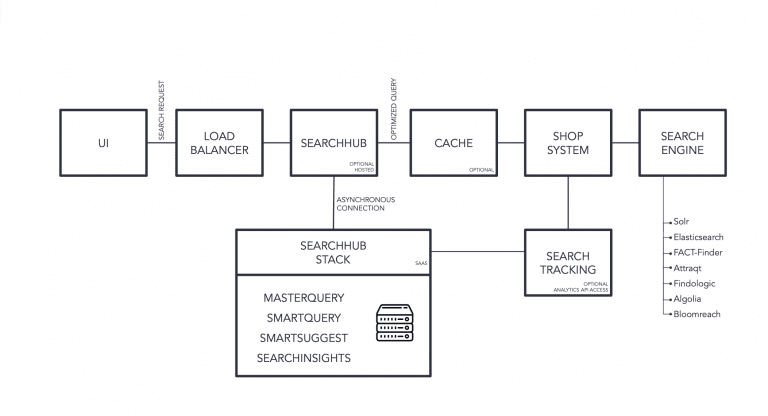
This architecture gives our customers the freedom to deploy our smartQuery Serving-Layer wherever they want, reducing latencies to the bare minimum (<1ms 99.5 conf interval) as there is no additional internet-latency. While it gives us the freedom to entirely focus on efficiently building & training the best available ML-Models consumed by the Serving-layers asynchronously. This freedom to deploy and operate such a thin client is one of the most appreciated features of searchHub and one key reason for our short integration times.
This architecture also enables our users to modify these models and deploy them to production without any IT-involvement on their end. Giving Relevance-Engineers, Data-Scientists and Search-Managers almost instant influence and optimization capabilities for their search & discovery platform.
4. AI-Powered Search Query Rewriting Is The Best Starting Point…
Again yes. Of course, at first glance we could have focused on more “fancy” areas of search, but the initial focus on thoroughly understanding the user-query was one of the best decisions we made. Why? Because you can’t control your users’ queries – they express their intent in their terms – and there is nothing you can do about it. Matching users’ intent to your document inventory is the key part of every search process. Therefore, it just felt natural to start here, even though it’s the most challenging part.
Once we had a solution to this problem in place, we were shocked at the additional benefits and opportunities that surfaced. The sparsity in behavioral data is automatically reduced, it removes 1000s of hours of manual curation and optimization whilst enabling more stable and consistent results. That’s why we are still investing significant effort into furthering this part of the platform, as every minor improvement here compounds up to the different down-stream tasks.
This year we will have processed over 25 billion searches resulting in almost 750 Million unique search phrases across 13 languages, empowering our customers to generate well over 5 billion € in GMV (Gross Merchandise Volume). All of that with a purposefully, minimal, highly skilled Dev and Dev-ops Team.
Time To Update You On Our Journey So Far
1. From Ok Data To Great Data
Since we work mainly with behavioral data, we depend heavily on the quality of their sources. Whilst almost everybody out there thinks that systems like Google Analytics, Adobe Analytics and others should be perfect sources, we learned the hard way that this is absolutely not the case. Therefore, we had no other choice as to build our own Analytics Stack (a combination of our searchCollector and searchInsights). At the beginning it was tough to convince our customers or potential customers that they needed it, but as soon as we were able to show them the difference, they directly fell in love. Being able to accurately track your search & discovery features, and getting direct feedback for potential improvements in consolidated views, not only gave our customers a 3-fold increase in operational efficiency but also dramatically improved the results delivered by searchHub.
2. Reducing The Noise From Search-Suggestions
Another area where we had to act were search-suggestions. We again assumed that state-of-the-art systems should have already solved the search-suggestions use case, but it turned out they did not. To correctly understand user intent, you first have to intercept it. However, a lot of search-suggestion systems negatively influenced user search behavior and there was nothing we could do about it. That’s why we built smartSuggest, and again it turned out to be a massive success. Not only does it handle the usual use case in a more efficient, consistent and less error-prone way, it also enables our searchHub users to instantly influence suggest behavior in terms of results and ranking again without any internal IT involvement.
3. The Bumpy Road To Transparency And Simplicity
Although our intent-clustering is very, very precise, it was always a black-box for customers and searchHub-users. For one, they wanted to, at least, get an idea about what’s going on under the hood. And secondly, they wanted to directly incorporate their expertise into the system. Everybody involved in ML (Machine Learning) is aware of how complex it is to explain why the systems do what they do. But we found a way by creating what we call “meta-patterns”. Things like this change was done because the engine has certain knowledge about the case, vs. this change was implicitly learned by observing this particular behavior. We now tag every change in the clustering pipeline with one or multiple of these patterns, giving our customers maximum transparency.
Additionally, we found a very efficient way for our customers to add their domain knowledge to the system without them having to take care of the little ugly details and pitfalls. We officially call this feature AI-Training, while our customers call it “Search-Tinder”. Because it follows the same basic UX principle of is there a match or not.
4. Encode It If You Can
Another colossal pile of work which was mostly done under the radar is represented by our newly introduced smartSearchData-Service, which is still in beta-status. If you frequently follow us, you might already be aware that searchHub was always limited by the quality of the underlying search platform. This means that for a given Intent-cluster we were only able to automatically pick the best available query, but we were unable to further improve the result for this query. Of course, we could have gone all-in on query-parsing (automatically building more complex search-platform dependent queries) but this would only have been possible with massive downsides for our customers and us. Chiefly among them: the implementation-effort would have exploded. But not only that, we would have limited the freedom of our users to improve their Search & Discovery platforms on their own.
That’s why we again decided for a radically different approach. While query processing is different for almost any site search platform, their underlying structure of indexable objects is not so different. So, what if we could somehow encode the needed additional information (to get better results for a given query) directly into the indexable objects without the need to dramatically change the query processing? That’s precisely what we do right now. It might not be a complete feature yet, and we may still face some real challenging problems in these areas, but the results so far are very encouraging.
Closing Comments
We as a team are really proud of what we have achieved, and we know it’s just the beginning. All of us are genuinely grateful and thankful for all our fantastic customers, users, partners, and fans out there which made all of this possible. It’s their feedback, and patronage, that keeps the wheel spinning and the lights on. Therefore, we hope that all of you are as eagerly looking forward to the next 5 years as we are.