What’s Actually Wrong With Ecommerce Search
This is Part 1 of “The Search Tax” — a three-part series about what ecommerce search actually costs you, who’s profiting from the dysfunction, and what it would take to stop paying.
The tax nobody puts on the invoice
Every ecommerce company pays a search tax. It’s not on your P&L statement. It doesn’t show up in your vendor contract. But it’s there — in the hours your team spends fixing what your search engine should already handle, in the revenue lost to zero-results pages, and in the customers who leave because your suggest dropdown couldn’t parse a misspelling.
The ecommerce search industry has matured in tooling but not in outcomes. Search engines have become faster, more configurable, more API-friendly. And yet the fundamental problems — bad suggestions, irrelevant results, zero-results dead ends — persist at roughly the same rate they did a decade ago.
That’s not a technology problem. It’s an architecture problem.
Search engines need humans to function
Here’s the uncomfortable truth that no search vendor puts on their website: every search engine, proprietary or open source, requires continuous human optimization to deliver acceptable results.
Synonyms. Redirects. Query rules. Boosting logic. Ranking overrides. These aren’t edge-case configurations. They’re the core work that makes search function. Remove the human doing this work and the search degrades — not slowly, but within weeks.
Only 15% of ecommerce companies have dedicated search resources. The other 85% distribute search tasks across merchandising, marketing, or development teams. For those teams, search optimization isn’t strategy. It’s triage. Fix what broke today. Hope it holds until tomorrow.
The search tax here is invisible: it’s the salary of the person whose job is to compensate for what the technology doesn’t do. And the better they are at it, the harder it becomes to separate their work from the system’s capability. Try explaining to a CFO that your search only works because one person maintains 4,000 synonym rules in a spreadsheet. That’s a fragile business.
Tracking that captures a fraction of reality
Most search analytics depend on session-based tracking. Sessions depend on cookies. Cookies depend on user consent. In Europe, where GDPR has teeth, opt-in rates hover around 30%.
That means 70% of your search traffic is invisible. Your analytics dashboard — the one you use to decide which queries to optimize, which synonyms to add, which results to promote — is built on roughly a third of reality.
And even that 30% is unreliable. Sessions expire. Users switch devices. Cookie data fragments the journey into disconnected snapshots. You’re making optimization decisions based on a partial, distorted picture and calling it “data-driven.”
The search tax here is decision quality. You’re paying for analytics that can’t tell you what’s actually happening. And the decisions you make from that data compound: wrong synonyms, misplaced redirects, optimizations that solve problems for the 30% you can see while ignoring the 70% you can’t.

The zero-results page: your most expensive dead end
A zero-results page is a customer who showed up ready to buy and was shown a blank wall.
Most search engines handle zero-results reactively. The query fails. The page loads empty. Maybe a “Did you mean…?” suggestion appears — usually wrong. The customer reformulates, tries again, or leaves.
The cost isn’t just the lost transaction. It’s the lost trust. A customer who hits a zero-results page is 3-4x less likely to use search again during that session. They’ve learned that your search doesn’t understand them. That lesson sticks.
The root cause is almost always the same: the search engine treats every query as an independent text string. It has no concept of intent. “Bxsprngbett,” “box spring bett,” “boxspringbed,” and “boxspring matratze” are four different queries to the engine. To the customer, they’re all the same thing: “I want a box spring bed.”
This isn’t a hard problem to describe. Thousands of query variants mapping to one purchase intent. But it is a hard problem to solve manually — which is exactly how most teams try to solve it. One synonym at a time. One redirect at a time. Until the synonym list is 4,000 entries long and nobody remembers why half of them exist.
The suggest layer nobody thinks about
43% of ecommerce shoppers start with search. Their first interaction isn’t with your results page or your product cards. It’s with your autocomplete dropdown.
And that dropdown, in most implementations, ranks suggestions by query frequency. The most popular queries appear first. Type “sh” and get “shoes,” “shirts,” “shorts” — whatever was typed most often, regardless of what the person typing right now is actually trying to buy.
This is the digital equivalent of a shop assistant who responds to every question with “most people ask about shoes.” Technically true. Practically useless.
The suggest layer is the steering wheel of your search experience. It shapes what customers search for before they even press enter. And on most ecommerce sites, it runs on a popularity contest instead of purchase intent.
Nobody audits it. Nobody A/B tests it. Nobody asks whether the suggestions are actually leading to conversions. It just sits there, completing words, while the team optimizes everything downstream of it.
The compounding cost
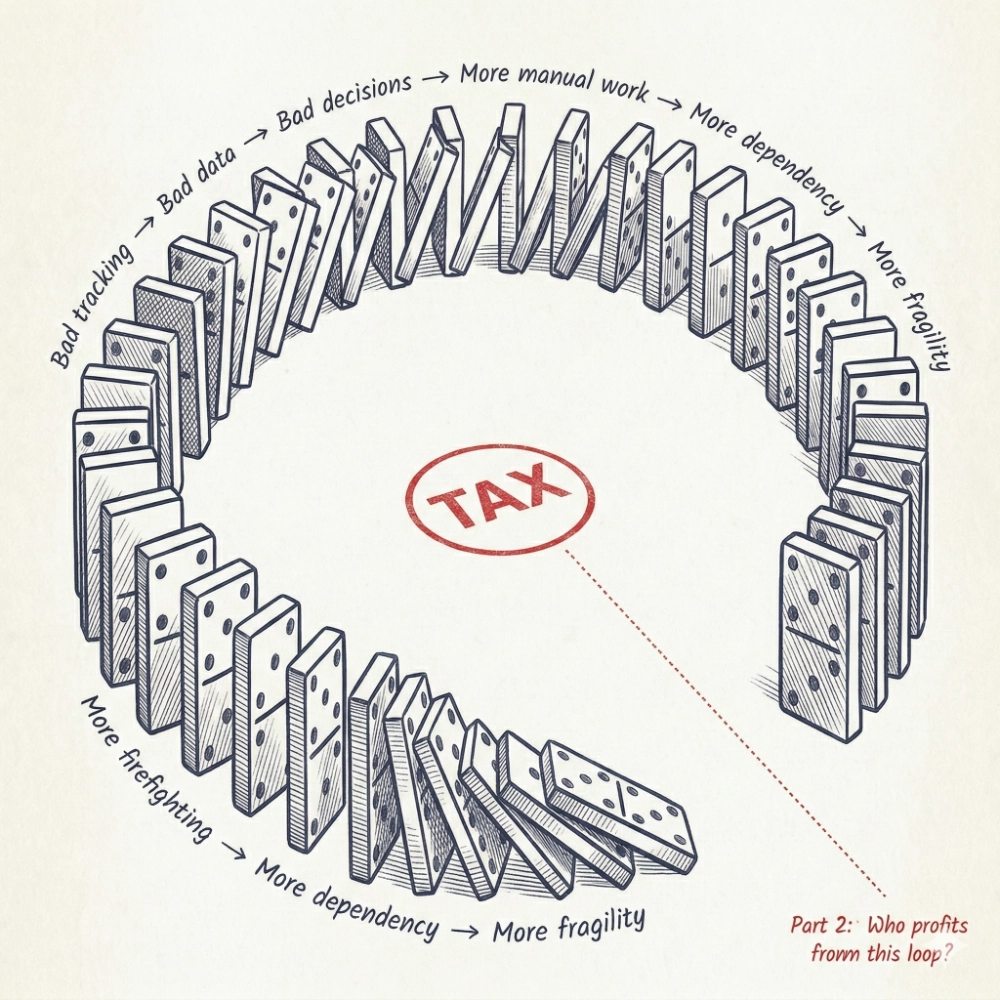
These problems don’t exist in isolation. They compound.
Bad tracking means bad data. Bad data means bad optimization decisions. Bad decisions mean more manual work. More manual work means more dependency on humans. More dependency means more fragility. More fragility means more firefighting. And more firefighting means less time to question whether the architecture itself is the problem.
That’s the search tax. Not one line item, but an entire loop of inefficiency that feeds itself. And the cruelest part: the people paying it are usually too busy managing it to see it clearly.
In Part 2, we’ll look at who’s profiting from this loop — and why the promises made by search vendors are making it worse.




